
When working with a large dataset, it is common to come across outliers and noise (such as mistakes in data recording, irrelevant features, or data entry errors). Imagine that all of this is being fed as input to a machine learning algorithm. If the algorithm learns too well—to the point that the resulting model adjusts perfectly to the input data—then all these irregularities are being incorporated into the model. Now imagine someone trying to use this model to predict future outcomes. It is expected that the model will fail to predict new outputs, as it was trained to fit a very specific dataset without recognizing the underlying patterns. When this happens, the model is said to be overfitted.
Now consider a second scenario: the researcher successfully removed noise and outliers but created a model with too many parameters. When applied to the training set, the model captures all its variations in detail.
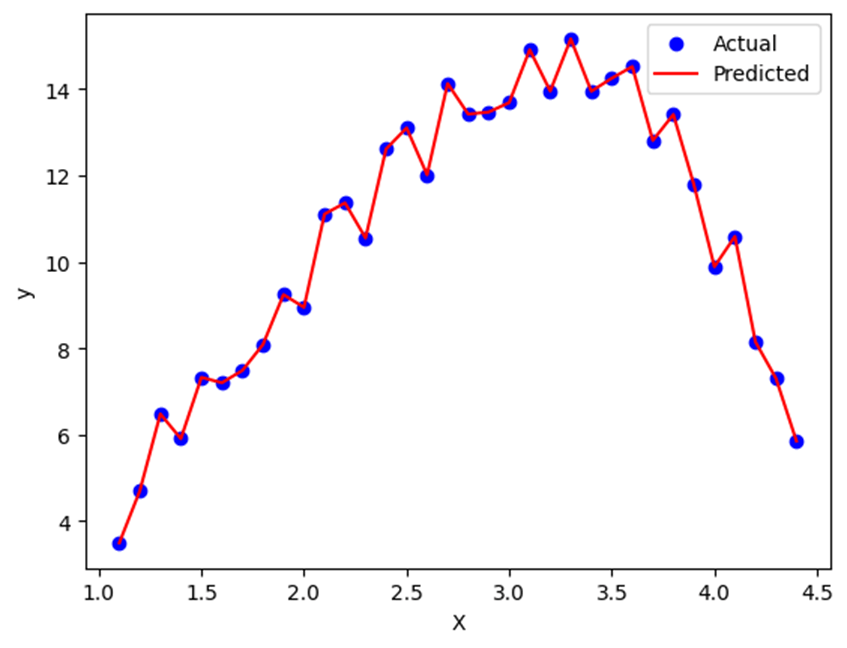
However, when the same model is applied to the test set, it is unable to generalize its behavior and fails to accurately predict the results.
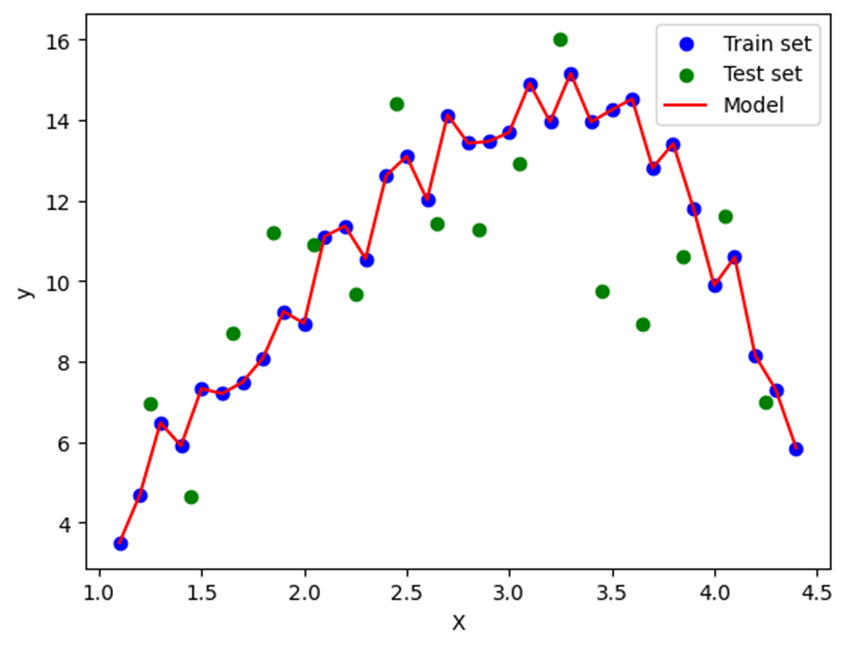
This is one of the biggest challenges in the field of machine learning: creating a model that captures the variability of the training set while maintaining enough generalization to make accurate predictions on new data. The common practice of splitting a dataset into a training set (typically 70% of the data) and a test set (the remaining 30%) aims to identify whether a model is overfitting.
It is important to watch out for overfitting because it highlights how analyzing a model’s individual parameters without context can be misleading. After all, the main goal of machine learning is generalization—and whenever a model is overfitted, it indicates poor predictive performance. Moreover, overfitting is often caused by choosing an overly complex model, which can lead to a waste of computational resources.
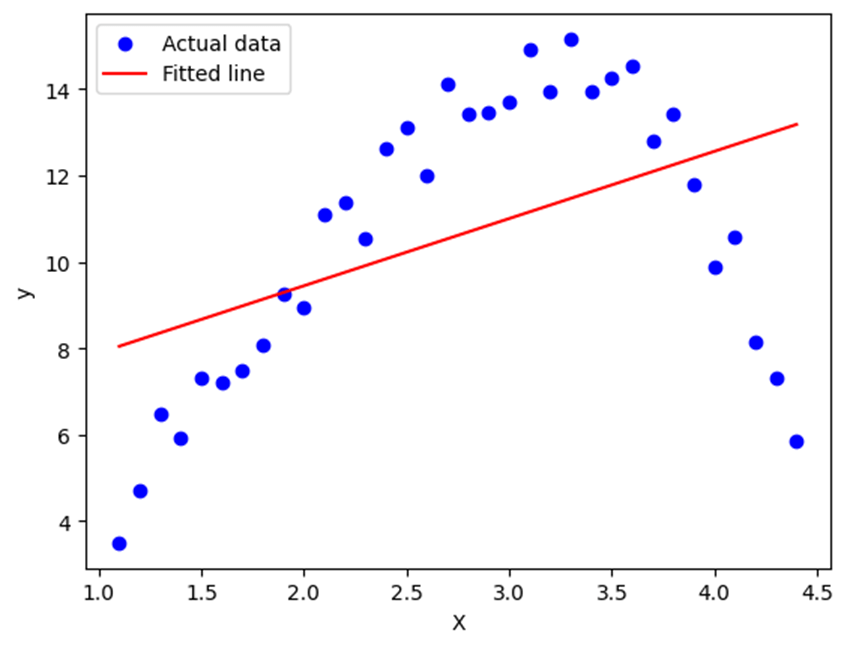
The opposite can also occur: when a model is too simplistic and unable to capture the variance in the data. In this case, we say that the model is underfitted, and the best solution is to increase the model’s complexity—either by adding more parameters or increasing the training time.
How to Prevent Overfitting
Simplifying the model by reducing the number of parameters (or layers, in the case of neural networks) is one of the first actions to consider. Increasing the amount of training data is also a useful strategy, as more data tends to help the model identify general patterns rather than memorizing specific examples.
Cross-validation is an excellent resampling technique that helps determine whether a model is underfitted or overfitted. The most common implementation is called k-fold cross-validation, which involves splitting the dataset into k equal parts (called folds). For each iteration, the model is trained on k – 1 folds and tested on the remaining fold. This process is repeated k times, and the results are averaged.
Another effective way to prevent overfitting is by applying regularization techniques. Regularization works by adding a penalty term to the model’s loss function, discouraging it from fitting too closely to the training data. This penalty helps reduce the complexity of the model by shrinking the weights of less important features. The most common approaches are L1 regularization (also known as Lasso), which can drive some weights to zero and effectively eliminate irrelevant features, and L2 regularization (or Ridge), which discourages large weights without making them exactly zero. Both techniques help the model focus on general patterns rather than memorizing noise, leading to better performance on unseen data.
In summary, overfitting is a critical challenge in machine learning that can significantly affect a model’s ability to generalize to new data. Recognizing its causes—such as excessive model complexity, insufficient or noisy data—and applying strategies like regularization, cross-validation, and simplification are essential steps in building robust models. While it’s tempting to focus on achieving high accuracy on the training set, true model performance is measured by its ability to make accurate predictions on unseen data. By staying mindful of overfitting, we can ensure that our models are not only powerful but also practical and reliable in real-world applications.

Leave a comment